Oddities in Casciaro, Gino, Kouchaki 2014
Following my replication, it was clear to me that the large effect originally reported in CGK2014 study 1 is implausible.
We also know that other datasets under the custody of Gino were altered: Could the large effect in study 1 be the result of data tampering?
It turns out that the data contains patterns consistent with this hypothesis.
library(tidyverse) # dplyr + gpplot2
library(patchwork) # composing plots
library(lsa) # cosine similarity
library(ggforce) # drawing ellipses in graphImplausibly long sequences of identical responses
We know that, in other datasets under the custody of Gino, someone changed responses to generate the desired pattern of results. If these changes were made at random throughout the data, it would be hard to detect. However, it is also possible that the person worked row-by-row, in which case we might see that adjacent rows or consecutive participants have very similar values.
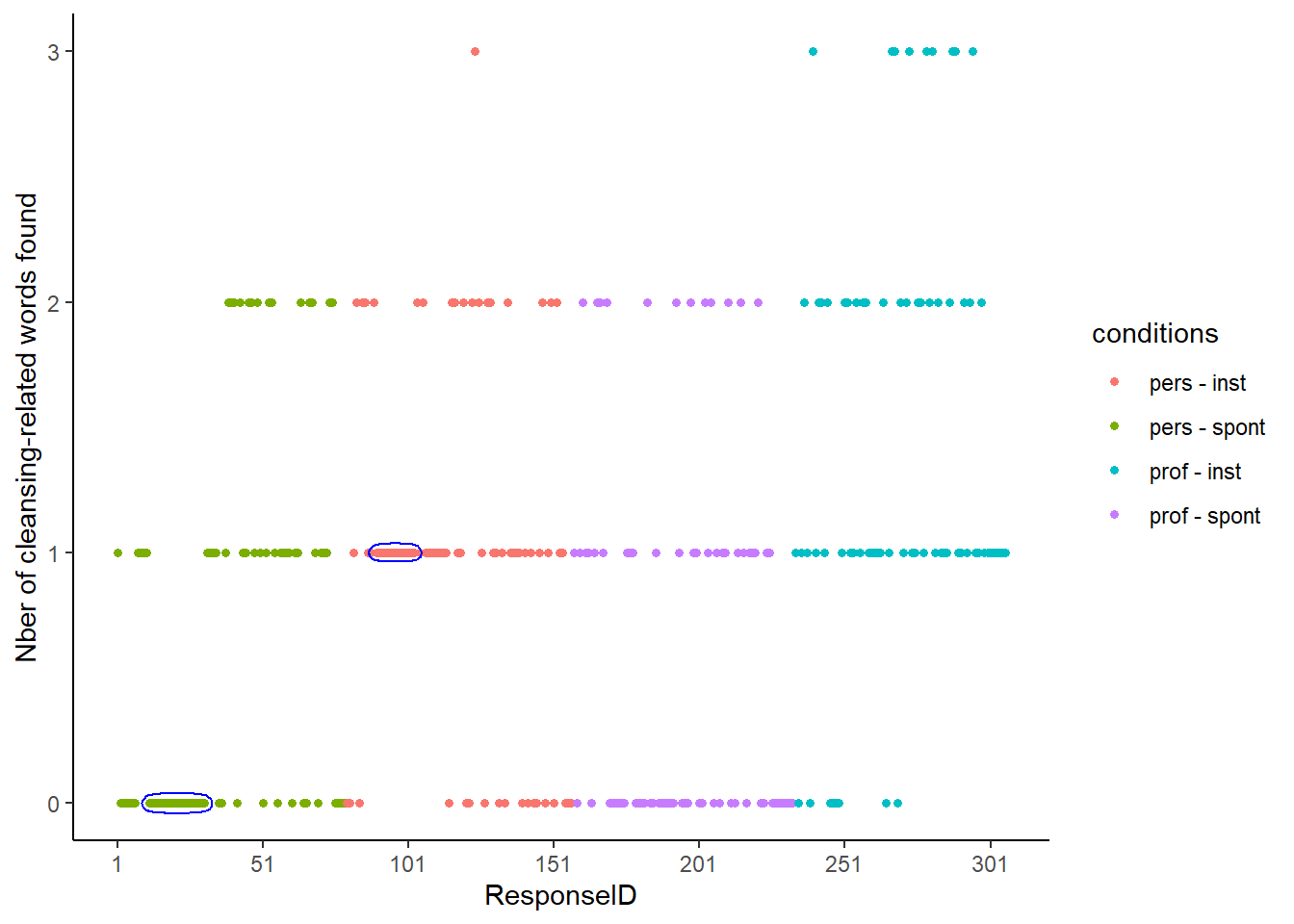
First, how does the data look like? It appears to be sorted by condition, and that a “ResponseID” (describing the row number of the data point) was then added.
The data does not appear to be sorted on any other column or combination of columns: We should thus not find any particular pattern in the sequence of responses.
When plotting the row number (column “ResponseID” on the x-axis) against the number of cleansing-related words that people find (y-axis), long “streaks” of identical responses appear:
- A streak of twenty consecutive “0” appears in the Personal-Spontaneous condition (a condition that was predicted to find few cleansing-related words).
- A streak of fourteen consecutive “1” appears in the Personal-Instrumental condition (a condition that was predicted to find more cleansing-related words)
To determine the likelihood of these streaks emerging by chance alone, I repeatedly shuffled the data per condition, and constructed a distribution of the”streak lengths” that I observed (i.e., the longest streak of consecutive values that I observed).
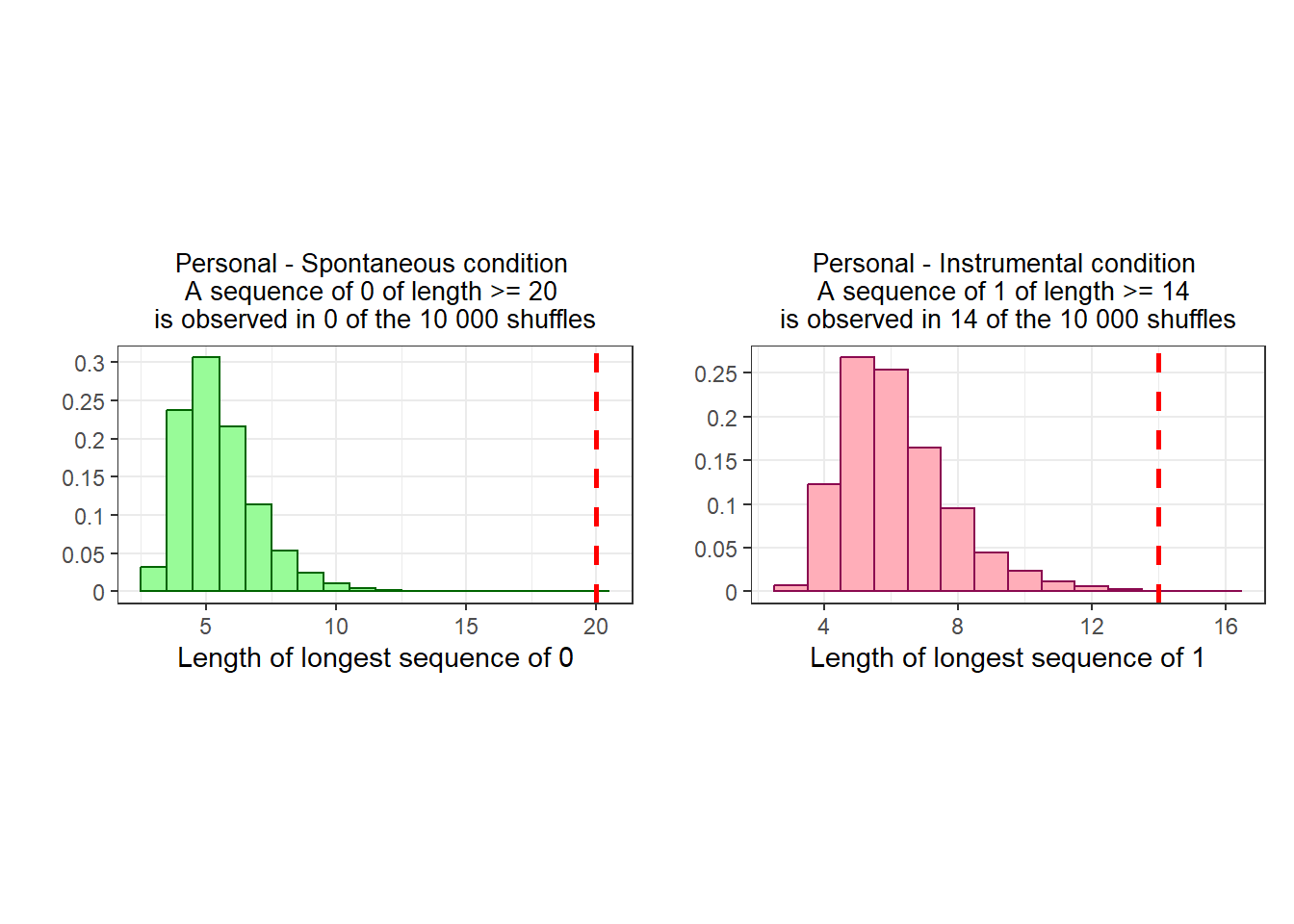
These sequences are very unlikely to be caused by chance:
A sequence of 20 or more zeroes never occurs.
A sequence of 14 or more ones occurs 14 times out of 10 000.
The words written by participants differ between the original and the replication
What would happen if changes were made?
If a person made changes to the dependent variable (i.e., the number of cleansing-related words the participant found: 0, 1, 2, or 3), they would also need to change the words themselves (which also appear in the data). If, for instance, you are changing a participant who found 1 cleansing word (e.g., completed the word stem W _ _ H as “wash”) into a participant who found zero cleansing word, you will need to replace the cleansing word that they found into a non-cleansing word (e.g., replacing “wash” by “wish”).
To do it well, however, you need to be sure that the words that you write in replacement match the overall distribution of words that the real participant wrote. If only 10% of the participants wrote “wish”, you do not want to write “wish” for every other participant you change: You’ll use “wish” parsimoniously so that this proportion remains unchanged.
A visual comparison
How would we know if the distribution of words has changed? We can compare the words that participants write in the original vs. the replication.
Specifically, we will look at the words people generate on the cleansing stems (“W _ _ H”, “S H _ _ E R”, “S _ _ P”) when they do not find the cleansing word (it doesn’t make sense to do this analysis when they do find the cleansing word, since there is only one possible answer).
The graph below shows all the trigrams that are present at least once in each dataset.
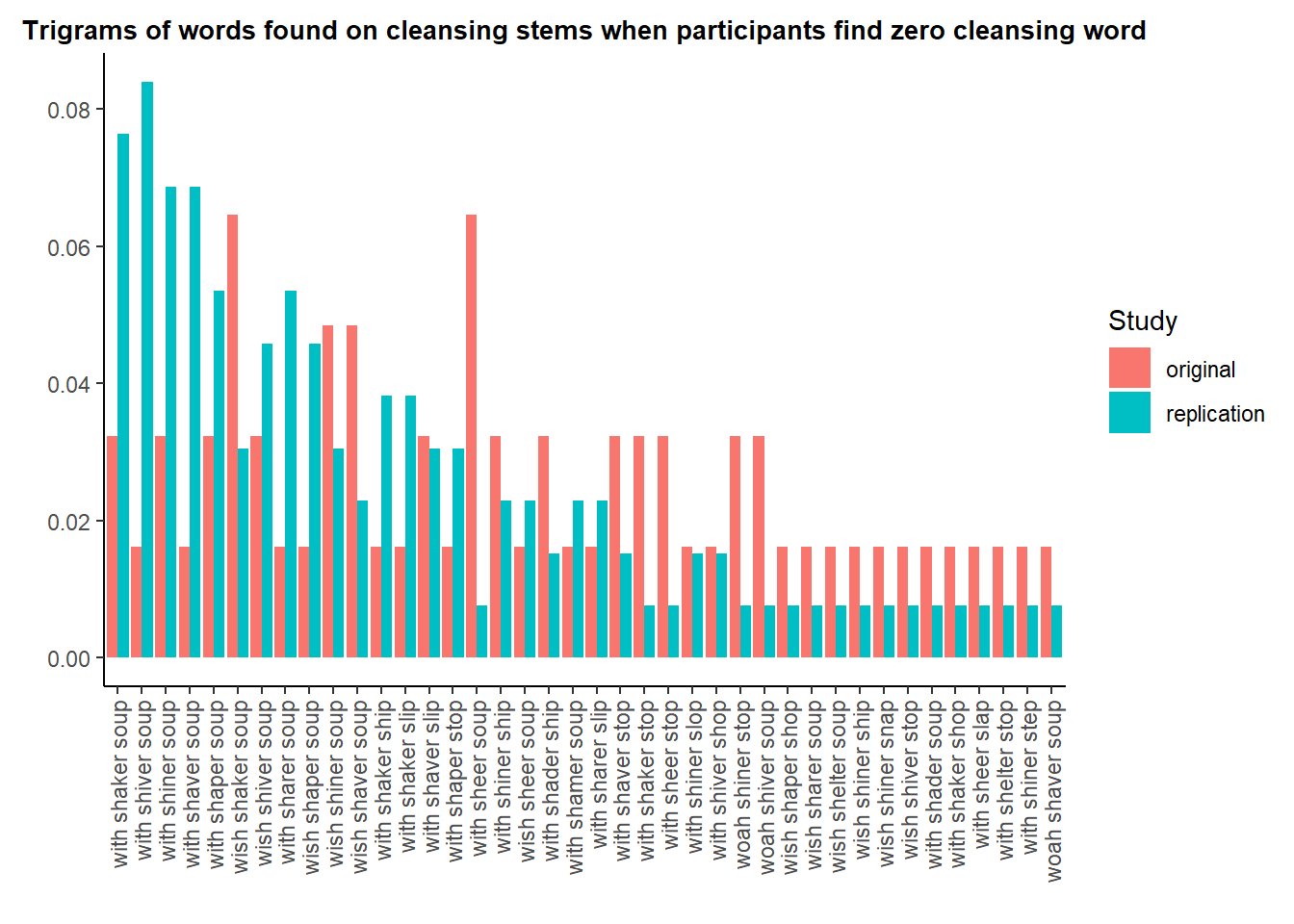
This chart shows large differences, for instance:
“with shiver soup” or “with shaver soup” is much more common in the replication.
“with sheer soup” is fourteen times more common in the original (4 times out of 306 observations in the original, once out of 1069 observations in the replication). It is all the more surprising that “sheer” is an error (it does not match the stem “S H _ _ E R”).
A formal analysis of similarity
A placebo test
The previous evidence shows that the distribution of cleansing words found by participants in the original dataset doesn’t match that of the replication. It might be because the original data has been tempered… Or because the MTurk population has changed.
An alternative explanation to these changes is indeed that the population on MTurk may have changed between the moment the original study was run (before 2014) and the moment the replication was run (in Spring 2021). If the population has changed, maybe the words that come to people’s mind has changed as well.
We can apply a placebo test to verify this hypothesis: If this explanation is correct, then we should also find that the words found for the non-cleansing steams (“F _ O _”, “B _ _ K”, “P A _ _ R”) differ between the original and the replication.
We do not find that. The words found for the non-cleansing steams, and their distribution, is as similar as expected between the original and the replication.
Visually, first: No major difference appears in the proportions of words chosen for the neutral stems between the original and the replication. Since there are many more options, I only plot the histogram of the trigrams that are found at least twice in each dataset.
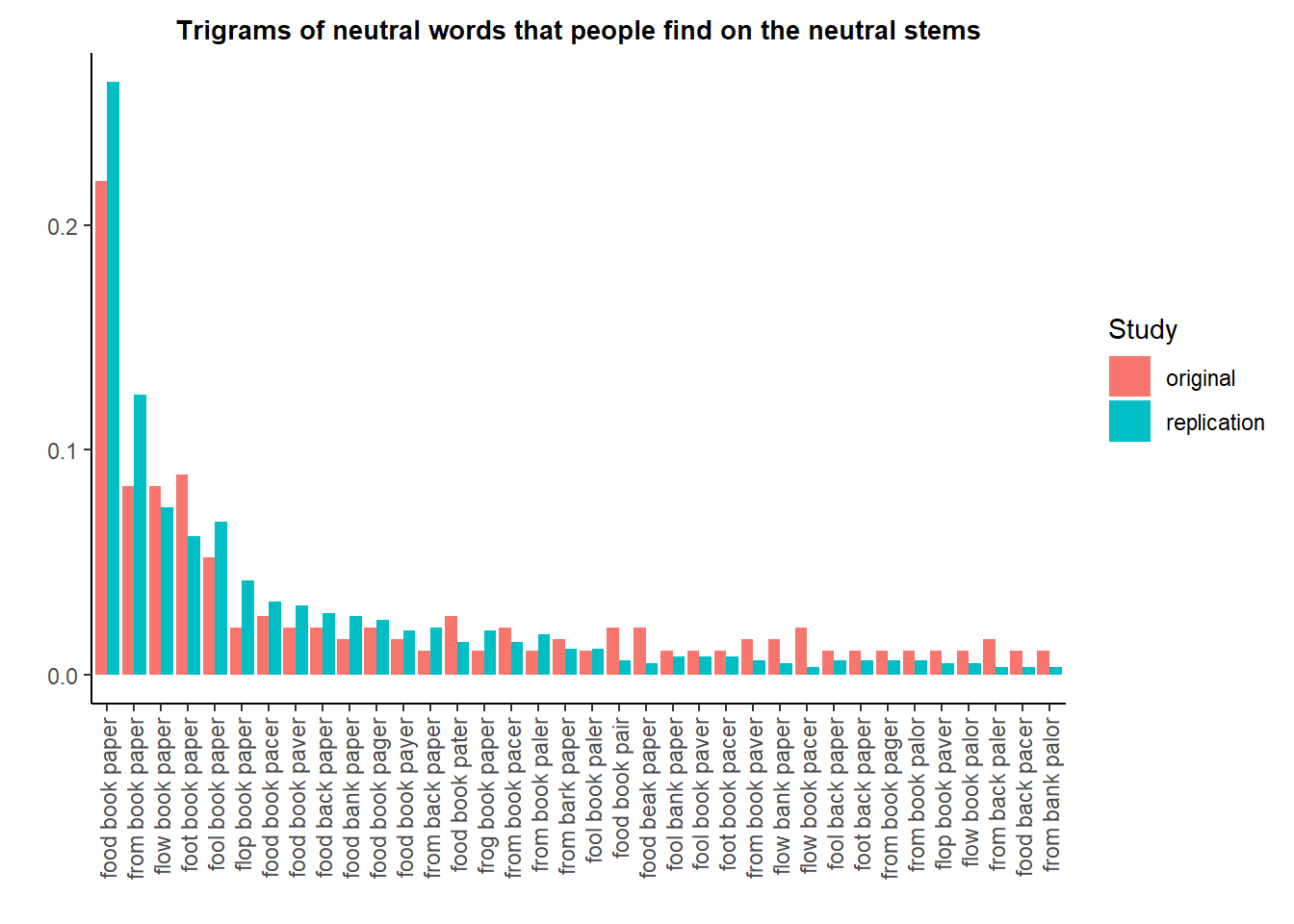
Contrary to what we saw on the cleansing stems, the proportions appear very balanced between the original and the replication.
To test if this dissimilarity is greater than what would be expected if the words came from a common population, I used the Cosine similarity of the words frequencies.
I consider the words written in the original and in the replication as two different “bags of words”.
I compare the frequencies of the words found in those two “bags of words” by computing their cosine similarity. The lower the cosine similarity, the more dissimilar the two “bags of words”.
I look how often we would find the two bags of words to be this dissimilar if I re-allocated the words at random between the original and the replication (i.e., if the two “bags of words” were drawn from the same distribution).
The graphs below present the results of this re-sampling procedure:
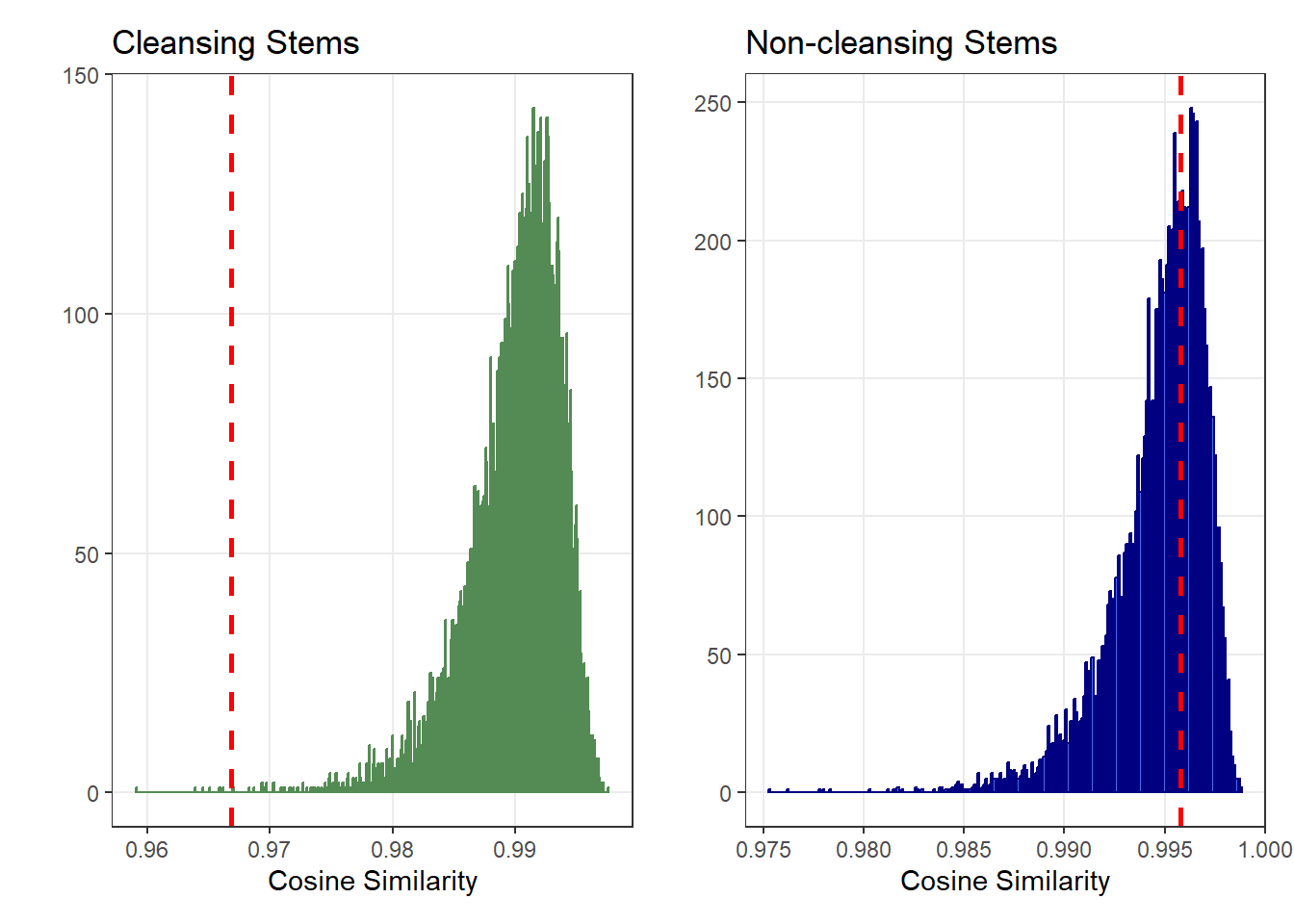
This confirms the visual observation:
When participants do not find cleansing-related words on the cleansing stems, they find different words in the original (vs. replication): The word frequencies are much more dissimilar than expected from random chance.
In contrast, the words that they find on the neutral stems are about as similar as expected between the original and replication.
Conclusion
These anomalies (improbable sequences of consecutive 0 or 1 in participants’ responses - which suggest that the participants’ responses are not independent from one another, and participants who find different words in the replication compared with the original, but only on the cleansing stems - which suggest that the words found on the cleansing stems have been changed), combined with the failure to replicate the effect, suggest that the integrity of the data has been compromised.
And now what?
Well… As I wrote before, it is very unlikely that data have been tempered only in the four initial papers that are now retracted.
As I wrote before as well, Casciaro, Gino, Kouchacki, 2014, suffers, above and beyond study 1, from multiple theoretical and methodological issues that should reorient the efforts of academics working on networking behaviors towards other potentially more fruitful avenues of exploration.
The Many Co-Authors Project indicate that out of the 223 papers for which Gino was involved in the data collection / analysis of one study or more, only 6 papers have been or will be retracted (4 of them were already retracted before the MCAP).
But at least there was an attempt (in spite of the lawsuit) to do something among Gino’s co-authors… The silence is deafening among Ariely’s co-authors…
This is maybe the biggest lesson the scientific community should draw from this scandal: it is impossible - IMPOSSIBLE - to clean the scientific field once fraudulent papers have entered the scientific record. Because most journals refuse to put in place the policies that would allow to catch such cases before they get published, the scientific community is condemned to keep building on sand castle, unicorns and other magic effects obtained after too many corners have been cut.
Journals have been and remain a major problem!
Zoé Ziani
PhD in Organizational Behavior